
Cet article est le premier d’une série consacrée au Deep Learning : Après avoir présenté dans les grandes lignes le fonctionnement et les applications des réseaux de neurones, vous découvrirez plus en détails dans les articles suivants les principaux types de réseaux et leurs architectures, ainsi que des méthodes et divers exemples d’applications du Deep Learning aujourd’hui. Démarrons sans plus tarder notre Introduction au Deep Learning.
Les concepts clés : IA, Machine Learning, et Deep Learning
Depuis quelques années, un nouveau lexique lié à l’intelligence artificielle s’est imposé et il est parfois difficile de s’y retrouver. Lorsqu’on parle d’IA, on fait souvent référence à des technologies associées comme le Machine Learning et le Deep Learning. Pour clarifier, voici les définitions et la hiérarchie à retenir (IA > ML > DL).
- L’intelligence artificielle : champ de recherche qui regroupe l’ensemble des techniques et méthodes visant à concevoir des systèmes capables d’imiter des capacités humaines (perception, décision, langage, planification).
- Le Machine Learning : ensemble de techniques donnant la capacité aux machines d’apprendre automatiquement des règles à partir de données, par opposition à des règles entièrement prédéterminées par programmation.
- Le Deep Learning (apprentissage profond) : sous‑ensemble du Machine Learning reposant sur des réseaux de neurones artificiels comportant de nombreuses couches dites cachées, capables d’extraire automatiquement des caractéristiques à partir de grandes quantités de données.
Tableau de synthèse
| Niveau | Objet | Définition synthétique | Techniques typiques | Exemples d’applications |
|---|---|---|---|---|
| IA | Systèmes « intelligents » | Discipline englobant toutes les approches qui visent à reproduire ou simuler des capacités humaines. | Raisonnement symbolique, systèmes experts, planification, vision, NLP, Machine Learning | Assistants vocaux, robots, moteurs de recherche, systèmes de recommandation |
| ML | Apprentissage à partir des données | Méthodes qui apprennent des modèles et des règles à partir d’exemples. | Apprentissage supervisé, non supervisé, par renforcement; régression, SVM, forêts aléatoires | Prédiction de demande, détection de fraude, segmentation clients |
| DL | Réseaux de neurones profonds | Réseaux multicouches qui extraient automatiquement des représentations hiérarchiques des données. | Réseaux convolutionnels, récurrents, transformeurs; entraînement sur GPU | Reconnaissance d’images et de parole, traduction, conduite assistée, IA générative |
À retenir : tout modèle de Deep Learning est un cas particulier de Machine Learning, et tout Machine Learning relève de l’IA. Le Deep Learning se distingue par l’apprentissage hiérarchique de caractéristiques et par des besoins souvent plus importants en données et en puissance de calcul.
Machine Learning : quels types d’apprentissage existent ?
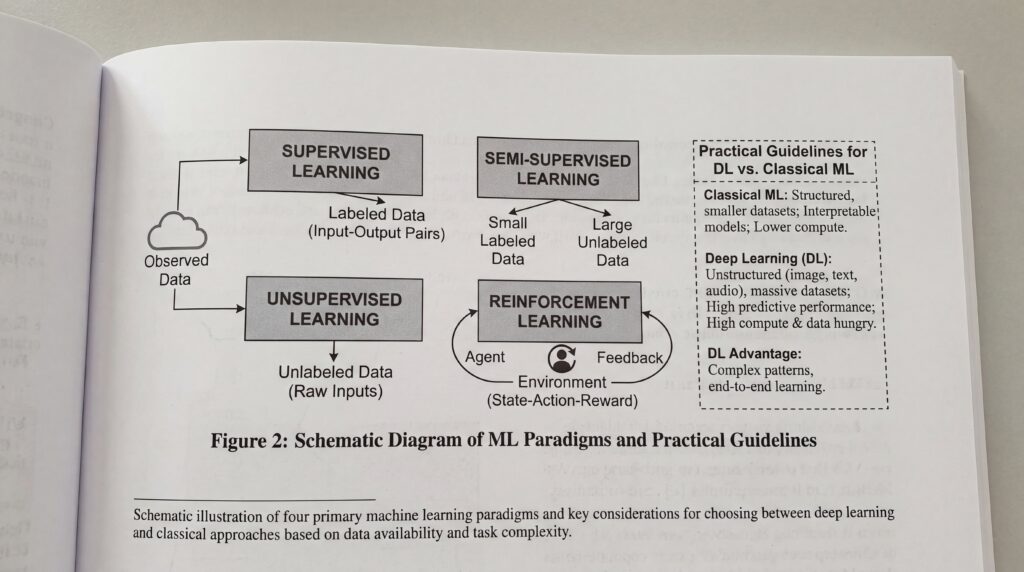
Au-delà du couple bien connu “supervisé/non supervisé”, le Machine Learning regroupe plusieurs paradigmes adaptés à des besoins différents. Panorama rapide, puis conseils pratiques pour savoir quand recourir au Deep Learning.
- Apprentissage supervisé : l’algorithme apprend à partir de données étiquetées pour prédire une valeur ou une classe.
- Apprentissage non supervisé : l’algorithme explore des données non étiquetées pour en révéler la structure (regroupements, facteurs latents).
- Apprentissage semi‑supervisé : combine un petit jeu de données étiquetées avec un grand volume non étiqueté pour améliorer les performances.
- Apprentissage par renforcement (RL) : un agent agit dans un environnement et apprend par récompenses cumulées.
Apprentissage supervisé vs non supervisé
En supervisé, le modèle est guidé par des exemples où la sortie attendue est connue. L’entraînement ajuste les paramètres pour réduire l’écart entre prédiction et vérité terrain, puis généraliser à de nouveaux cas. En non supervisé, il n’y a pas d’étiquettes : l’objectif est de déduire des structures présentes dans les données (groupes, segments, anomalies) sans critère de réussite explicite.
Exemples concrets :
- Supervisé : filtrage d’emails spam/ham, prédiction de la demande ou du prix d’un bien immobilier à partir d’historiques étiquetés.
- Non supervisé : segmentation client par regroupements avec des méthodes de k-means ou de classification ascendante hiérarchique (CAH) ; regroupement d’images de fleurs par similarité de forme et de couleur sans connaître l’espèce.
Et le semi‑supervisé, ça change quoi ?
Quand l’étiquetage est rare ou coûteux, le semi‑supervisé tire parti d’un petit jeu de données labellisé et d’un grand volume non labellisé. Le modèle apprend d’abord avec les étiquettes, puis exploite les données brutes pour mieux structurer l’espace des représentations et gagner en précision, notamment lorsque les classes sont difficiles à séparer.
Cas concret : disposer de 2 000 images médicales annotées et de 100 000 non annotées. On entraîne sur les images étiquetées, puis on affine en utilisant les non étiquetées pour renforcer la cohérence des prédictions. Résultat attendu : meilleure généralisation qu’un entraînement purement supervisé de petite taille.
Apprentissage par renforcement, en quoi est‑il différent ?
Le RL se distingue car il n’apprend pas sur un jeu d’exemples étiquetés, mais par interaction avec un environnement. Un agent observe un état, choisit une action, reçoit une récompense, puis optimise une récompense cumulée sur le long terme. Il est souvent associé au Deep Learning pour approximer des politiques ou des fonctions de valeur dans des espaces complexes. Exemple emblématique : les avancées ayant contribué aux performances d’AlphaGo dans le jeu de Go.
À retenir : privilégier le RL pour des décisions séquentielles avec retour différé (robotique, contrôle, recommandation interactive), plutôt que pour une simple classification statique.
Quand préférer le deep learning au ML “classique” ?
- Beaucoup de données : le Deep Learning excelle quand on dispose de volumes massifs pour l’entraînement.
- Données non structurées : images, audio, vidéo, texte, où des réseaux de neurones apprennent les caractéristiques automatiquement.
- Forte non‑linéarité/complexité : relations difficiles à capturer par des modèles plus simples.
- Performance au plafond avec des méthodes classiques : le DL peut franchir un palier de précision.
- Accès au calcul accéléré : entraînement et inférence profitent de GPU et d’architectures modernes.
- Transfert d’apprentissage possible : modèles pré‑entraînés utiles quand les données étiquetées sont limitées.
À l’inverse, pour des données tabulaires modestes avec besoin d’interprétabilité et de réactivité sans GPU, démarrez souvent par des modèles “classiques” (arbres de décision, forêts aléatoires, SVM). Passez au Deep Learning lorsque la nature des données ou le niveau de performance requis le justifient réellement.
Qu’est-ce que le Deep Learning ?
Le Deep Learning (apprentissage profond) est un sous-ensemble du machine learning qui entraîne des réseaux de neurones artificiels comportant plusieurs couches cachées à apprendre automatiquement des représentations utiles à partir de grandes quantités de données. Plus les données et la profondeur du réseau sont importantes, plus le modèle peut capturer des motifs complexes, au prix de ressources de calcul élevées.
Opérationnellement, on l’emploie lorsque les règles sont trop nombreuses ou trop subtiles pour être codées à la main : vision, parole, texte, séries temporelles. Le cycle type consiste à préparer des données, entraîner un modèle, le valider puis le déployer pour prédire en continu.
Une définition simple
Le Deep Learning consiste à empiler des couches de neurones artificiels pour transformer des données brutes en une prédiction ou une décision, sans écrire explicitement les règles.
Pourquoi “profond” ?
Le terme profond renvoie au nombre de couches cachées. Chaque couche apprend des caractéristiques plus abstraites que la précédente, ce qui crée une représentation hiérarchique : bords et textures, puis formes, puis objets entiers.
Exemple : pour distinguer un chat d’un chien sur une image, les premières couches détectent des motifs simples (bords), les suivantes repèrent des formes (oreilles triangulaires, museau), et les plus profondes combinent ces indices pour classer l’animal. Lors de l’apprentissage, l’algorithme ajuste les poids des neurones de façon à réduire l’écart entre les résultats obtenus et attendus.
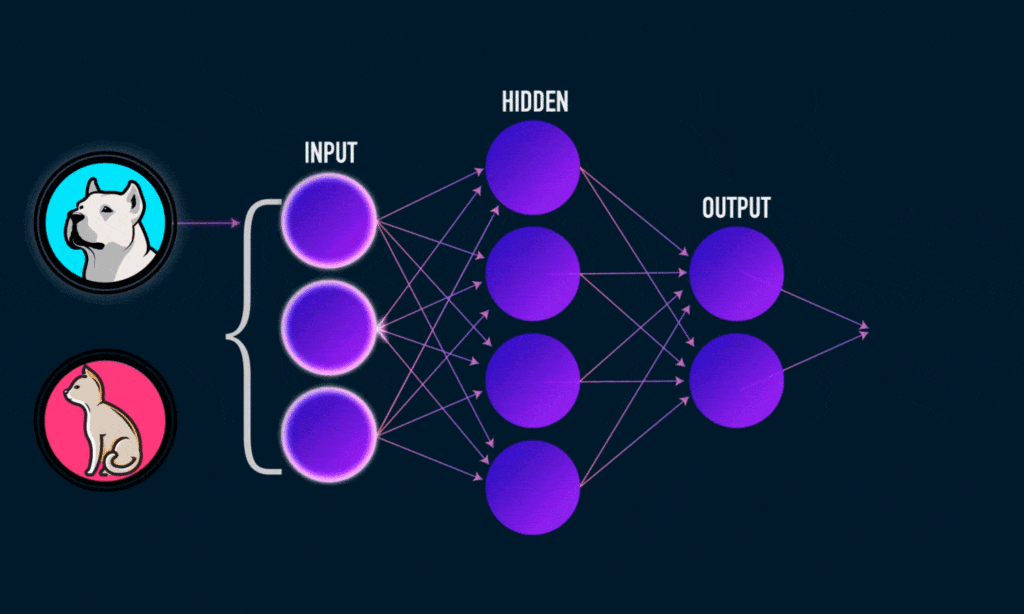
Réseaux de neurones artificiels : neurones, couches, activations
Chaque neurone artificiel peut être vu comme un petit modèle linéaire. En les connectant par couches et en appliquant des fonctions d’activation non linéaires, l’ensemble devient un modèle très flexible capable de capturer des relations complexes.
- Neurone : somme pondérée des entrées + biais, puis application d’une fonction d’activation.
- Couches : entrée, une ou plusieurs couches cachées, sortie. La profondeur correspond au nombre de couches cachées.
- Fonctions d’activation : ReLU ou tanh pour les couches internes, softmax en sortie pour obtenir des probabilités en classification.
- Paramètres appris : poids et biais ajustés durant l’entraînement par rétropropagation et descente de gradient.
À quoi ressemble un pipeline DL simple ?
- Données : collecter, étiqueter et fractionner en apprentissage et validation.
- Entraînement : initialiser le réseau et optimiser ses paramètres sur les données d’entraînement.
- Validation : évaluer sur un jeu dédié, ajuster les hyperparamètres et prévenir le surapprentissage.
- Déploiement : exporter le modèle, le servir en production et suivre ses performances.
Deep Learning et réseaux de neurones : biologiques ou artificiels ? Même combat
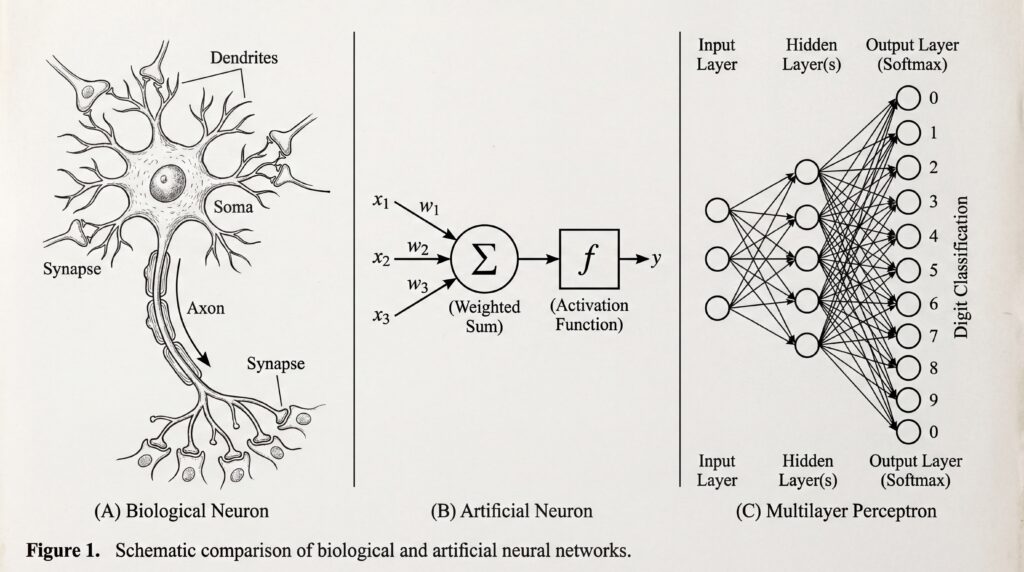
Pour comprendre l’apprentissage profond, rien de tel que de relier biologie et IA. Les réseaux de neurones artificiels s’inspirent des neurones biologiques pour traiter des signaux, composer des représentations et décider.
Mais attention au raccourci : en biologie, des cellules communiquent par impulsions électriques et chimie, dans le temps et l’espace. En IA, un neurone artificiel reste une brique mathématique optimisée pour apprendre à partir de données numériques. L’analogie guide l’intuition, la mise en œuvre est différente.
Neurone Biologique : Structure et rôle
Un neurone biologique comporte trois éléments clés : des dendrites qui reçoivent les signaux, un corps cellulaire (soma) qui les intègre, et un axone qui transmet le signal de sortie vers d’autres neurones via des synapses. Les synapses modulent l’intensité de la connexion, un peu comme des « poids » qui renforcent ou affaiblissent l’influence d’un signal.
Exemple simple : si la somme des signaux reçus dépasse un seuil d’excitation, le neurone émet un potentiel d’action le long de l’axone. Sinon, il reste silencieux. Cette logique de sommation et de seuil, bien que simplifiée, nous servira de repère pour comprendre les modèles artificiels.
Quel est le lien entre les neurones biologiques et neurones artificiels ?
Inspiration : comme les dendrites et les synapses, un neurone artificiel reçoit des entrées (vecteur x), les pondère (vecteur w), effectue une somme puis applique une fonction d’activation f pour produire une sortie. Empilés en couches, ces neurones composent des représentations de plus en plus abstraites à partir des données brutes.
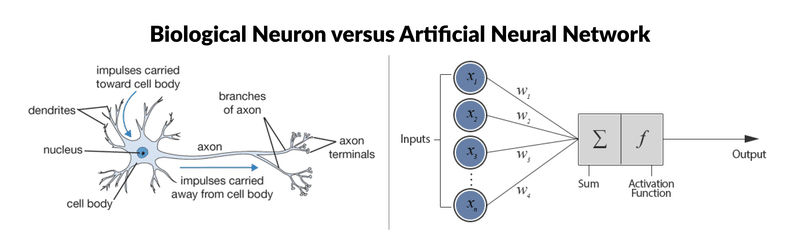
Différences : en IA, les signaux sont des nombres réels et les activations (ReLU, tanh, softmax) sont continues. L’apprentissage consiste à ajuster les poids pour réduire l’erreur, grâce à la rétropropagation du gradient, une procédure d’optimisation mathématique. Le neurone biologique, lui, émet des impulsions discrètes et ajuste ses connexions via des mécanismes de plasticité propres au vivant. En résumé : inspiration biologique, implémentation mathématique.
Principe de convolution : pourquoi s’inspirer de la vision humaine ?
En vision, le cerveau traite l’information par zones locales. Les réseaux de neurones convolutifs (CNN) reprennent cette idée : chaque filtre observe une petite fenêtre de l’image (champ réceptif), et le même filtre est appliqué partout dans l’image (partage de poids). Résultat : beaucoup moins de paramètres à apprendre, une meilleure sensibilité aux motifs répétitifs, et une robustesse aux translations (renforcée par le « pooling »).
Exemple : un filtre détecteur de bords « glisse » sur l’image pour répondre fortement là où il retrouve un contour. Empilés, ces filtres apprennent d’abord des motifs simples (bords), puis des formes (yeux, oreilles), jusqu’aux concepts utiles à la tâche (chat ou chien). Vous découvrirez ces architectures en détail dans notre article Convolutional Neural Network.
Repères historiques (du perceptron aux Transformers)
1. 1958 : Perceptron (Rosenblatt)
Premier modèle de neurone artificiel capable d’apprendre une séparation linéaire entre deux classes.
2. 1989 : Théorème d’approximation et essor des MLP
Des couches cachées non linéaires permettent d’approximer une large famille de fonctions. La rétropropagation relance l’entraînement des réseaux multicouches.
3. 1998 : LeNet-5
Réseau convolutif pour la lecture de chiffres manuscrits, première démonstration emblématique des CNN en vision.
4. 2012 : ImageNet et GPU
AlexNet remporte le concours ImageNet avec une large avance, grâce aux GPU, aux CNN profonds et à l’augmentation de données. Le deep learning s’impose.
5. 2017 : Transformers et attention
L’auto-attention remplace la récurrence pour modéliser des dépendances longues. Les Transformers deviennent la base des avancées récentes en traitement du langage et au-delà.
Entraîner un réseau profond : les bases
Former un réseau profond consiste à ajuster ses paramètres pour qu’il généralise bien sur de nouvelles données. En apprentissage supervisé, l’algorithme va ajuster les poids des neurones de façon à diminuer l’écart entre les résultats obtenus et les résultats attendus. Les modèles de Deep learning fonctionnent particulièrement bien avec une grande quantité de données, et l’entraînement s’appuie souvent sur des GPU, efficaces pour les calculs matriciels en parallèle.
Comment ça marche
- Préparer les données : nettoyer, normaliser, puis séparer en ensembles d’entraînement, de validation et de test.
- Créer des mini-batchs : regrouper les exemples par paquets pour exploiter le parallélisme matériel et stabiliser l’optimisation.
- Passage avant : les données traversent le réseau couche par couche pour produire une prédiction.
- Calcul de la perte : comparer la prédiction à la vérité terrain avec une fonction de perte (ex. entropie croisée en classification, MSE en régression).
- Rétropropagation : calculer les gradients de la perte par rapport aux paramètres.
- Descente de gradient : mettre à jour les poids avec un optimiseur (SGD, Adam) et un taux d’apprentissage.
- Boucle d’entraînement : répéter sur tous les batchs et sur plusieurs époques, en surveillant la validation.
- Ajustements : régler les hyperparamètres, appliquer de la régularisation, puis évaluer sur l’ensemble de test.
Données, batchs et époques
- Entraînement : sert à apprendre les paramètres du réseau.
- Validation : guide le réglage des hyperparamètres et détecte le surapprentissage.
- Test : mesure la performance finale sur des données jamais vues.
- Mini-batch : sous-ensemble du jeu d’entraînement traité en une itération. La taille de batch influence la stabilité et la vitesse.
- Itération : une mise à jour des poids sur un batch. Époque : passage sur l’intégralité des données d’entraînement.
- Shuffle : mélanger les exemples à chaque époque pour éviter les biais d’ordre.
Rétropropagation et descente de gradient, c’est quoi ?
La rétropropagation calcule, de la sortie vers l’entrée, l’influence de chaque paramètre sur la perte. La descente de gradient utilise ensuite ces gradients pour déplacer les poids dans la direction qui réduit la perte. En pratique, on choisit un optimiseur (SGD, Adam) et un taux d’apprentissage éventuellement piloté par un scheduler. Ce mécanisme itératif, répété sur des mini-batchs et des époques, est le cœur de l’entraînement.
En résumé : passage avant pour prédire, calcul de perte, passage arrière pour obtenir les gradients, mise à jour des paramètres, puis on recommence jusqu’à convergence en surveillant la validation.
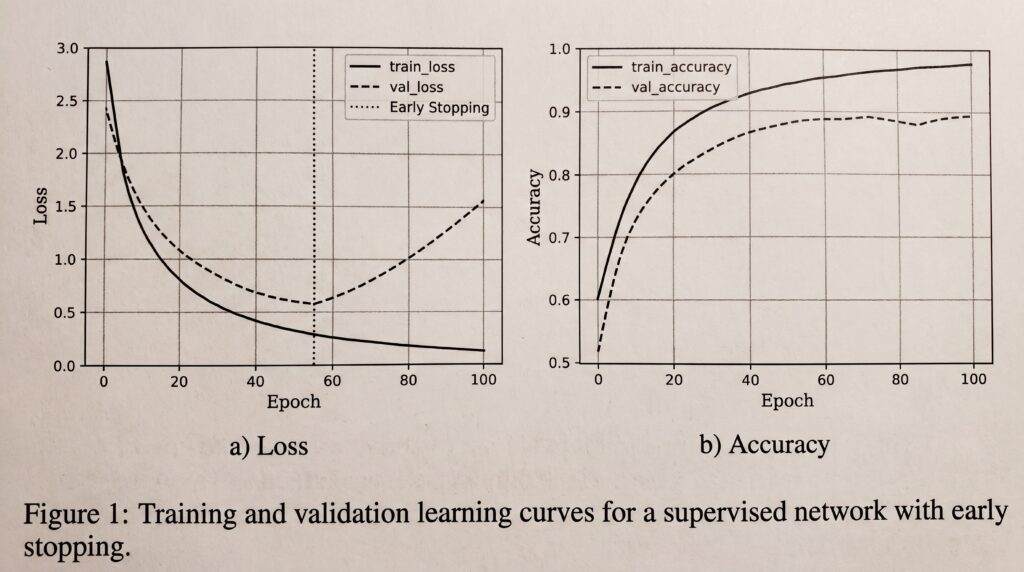
Overfitting vs underfitting : comment les éviter ?
Underfitting : le modèle est trop simple, il n’apprend pas les structures utiles. Overfitting : le modèle mémorise l’entraînement et se dégrade sur des données nouvelles. L’objectif est une généralisation équilibrée.
- Validation systématique : suivre la perte et les métriques validation, pas seulement l’entraînement.
- Capacité adaptée : ajuster la profondeur, le nombre de neurones et le nombre d’époques.
- Régularisation : poids pénalisés (L2), dropout, normalisation.
- Early stopping : arrêter quand la validation cesse de s’améliorer.
- Augmentation de données : générer des variantes réalistes pour enrichir l’entraînement.
Régularisation, early stopping et augmentation
- L2 / weight decay : pénalise les poids trop grands pour limiter la complexité effective.
- Dropout : désactive aléatoirement des neurones à l’entraînement pour éviter la co‑adaptation.
- Batch Normalization / Layer Normalization : stabilise et accélère l’entraînement, peut agir comme régularisation.
- Early stopping : surveiller la métrique validation avec patience et restaurer les meilleurs poids.
- Augmentation d’images : recadrage, retournements, rotations légères, jitter de couleurs, mixup/cutout selon les cas.
- Augmentation texte : synonymes contrôlés, suppression/échange de mots, back‑translation si pertinent.
- Augmentation audio : bruit de fond, décalage temporel, time/frequency masking.
- Bonnes pratiques : normalisation des entrées, taux d’apprentissage adapté, contrôle de la graine aléatoire, suivi des expériences.
Architectures majeures et cas d’usage
Chaque famille de réseaux de neurones possède un terrain de jeu privilégié. Le tableau ci-dessous synthétise où chaque architecture excelle, puis les sections détaillent les usages typiques et les points d’attention pour bien choisir.
| Architecture | Données typiques | Cas d’usage phares | Points forts | Limites |
|---|---|---|---|---|
| CNN | Images, vidéo, signaux 2D/3D | Classification, détection d’objets, segmentation | Invariance locale, paramétrisation efficace, transfer learning | Contexte global limité sans modules dédiés |
| RNN / LSTM / GRU | Séries temporelles, texte, audio séquentiel | Prédiction séquentielle, reconnaissance vocale, étiquetage séquentiel | Mémoire d’ordre, gestion des dépendances temporelles | Apprentissage plus lent, difficulté sur très longues séquences |
| Transformers et LLM | Texte, code, audio, vision (patchs) | NLP générationnel, recherche, agents, vision avancée | Attention, parallélisation, excellents résultats à grande échelle | Coût de calcul important, besoin en données |
| Auto‑encodeurs | Données non étiquetées variées | Réduction de dimension, débruitage, détection d’anomalies | Apprentissage auto‑supervisé, espace latent exploitable | Qualité dépend du signal pertinent reconstruit |
| GANs | Images, audio, vidéo | Génération réaliste, style transfer | Finesse des détails, photoréalisme | Entraînement instable, risques de mode collapse |
| Modèles de diffusion | Images, audio, vidéo, 3D | Génération, édition, inpainting | Stabilité d’entraînement, contrôle fin | Temps d’inférence plus long sans optimisation |
| GNN | Graphes: nœuds/arêtes/attributs | Recommandation, chimie, fraude, réseaux | Propagation de message, structure relationnelle riche | Scalabilité et qualité du graphe déterminantes |
CNN pour l’image et la vision
Les réseaux convolutifs exploitent des filtres apprenant automatiquement des motifs locaux (bords, textures, parties d’objets), ce qui les rend particulièrement efficaces pour la vision par ordinateur.
- Classification d’images: attribuer une étiquette à une image complète.
- Détection d’objets: localiser et classer des objets via des boîtes englobantes.
- Segmentation: découper l’image en régions cohérentes, au niveau des classes (sémantique) ou des instances.
Exemple métier: sur des radiographies, un CNN peut mettre en évidence des zones suspectes, facilitant la détection de fractures. Le transfer learning accélère souvent l’adaptation à un domaine spécifique à partir d’un modèle pré‑entraîné. Pour aller plus loin, consultez notre article dédié Convolutional Neural Network.
RNN / LSTM / GRU pour les séquences
Conçus pour les données ordonnées dans le temps, les RNN maintiennent un état caché qui résume le passé immédiat. Les variantes LSTM et GRU intègrent des mécanismes de portes qui limitent l’oubli d’informations pertinentes sur des horizons plus longs.
- Séries temporelles: prévision de demande, maintenance prédictive, détection d’événements.
- Texte: étiquetage séquentiel, analyse de sentiments, reconnaissance d’entités.
- Audio séquentiel: reconnaissance et synthèse vocale, diarisation.
Transformers et LLM : pourquoi dominent‑ils ?
Les transformers reposent sur l’attention, un mécanisme qui pondère dynamiquement les relations entre éléments d’une séquence. Leur architecture se prête à la parallélisation, ce qui favorise l’entraînement à grande échelle et explique leurs résultats de pointe en traitement du langage, puis en vision via les modèles de type Vision Transformer.
- Atouts clés: parallélisation efficace sur GPU, contexte long, pré‑apprentissage massif puis spécialisation, bonnes capacités d’in‑context learning.
- Usages phares: génération et recherche d’information, assistants et agents, résumé, traduction, classification, et, côté vision, classification, détection, segmentation avec des variantes adaptées.
- Points d’attention: besoin élevé en données et calcul, gouvernance des modèles et maîtrise des biais à prévoir dès la conception.
Auto‑encodeurs et détection d’anomalies
Un auto‑encodeur apprend à compresser une entrée vers un espace latent puis à la reconstruire. Si la reconstruction est médiocre pour un échantillon donné, l’erreur sert de signal d’anomalie. Ce principe fonctionne sans étiquettes, ce qui est précieux lorsque les cas rares sont difficiles à annoter.
Cas concrets: contrôle qualité visuel en usine, repérage d’opérations bancaires atypiques, surveillance IoT de capteurs, débruitage d’images médicales avant analyse par un autre modèle.
GANs et modèles de diffusion : quelle différence ?
Les GANs opposent un générateur et un discriminateur qui se co‑améliorent, ce qui peut produire des images très détaillées, au prix d’un entraînement parfois instable. Les modèles de diffusion apprennent à débruiter progressivement un échantillon, ils sont plus stables et offrent un contrôle fin, avec un temps d’inférence qui peut être plus long sans optimisation.
- GANs: photoréalisme élevé, utiles pour le style transfer et l’augmentation de données, mais risques de mode collapse.
- Diffusion: grande stabilité et qualité, édition d’images, inpainting et variations conditionnées, latence à gérer selon l’application.
Réseaux de neurones graphiques (GNN)
Les GNN propagent l’information le long des arêtes d’un graphe pour apprendre des représentations de nœuds, d’arêtes ou du graphe entier. Ils excellent quand la structure relationnelle compte autant que les attributs individuels.
Exemples: systèmes de recommandation basés sur interactions utilisateurs‑produits, prédiction de propriétés moléculaires en chimie, lutte contre la fraude en connectant clients, cartes, appareils et commerçants pour révéler des schémas anormaux à l’échelle du réseau.
À quoi sert le Deep Learning ?
Le Deep Learning excelle quand les volumes de données sont importants : ses réseaux apprennent des représentations utiles et continuent de progresser là où des approches plus classiques saturent. Porté par le big data et du matériel de calcul plus puissant, il s’applique à des tâches variées qui reviennent dans de nombreux produits numériques : voir, lire, comprendre, parler, recommander.
Classer, détecter, segmenter
- Classification d’images et de vidéos (exemple : reconnaître des visages, détecter des défauts de fabrication).
- Détection d’objets et suivi (personnes, véhicules, produits sur une chaîne de production).
- Segmentation sémantique et d’instances pour délimiter précisément des zones d’intérêt dans une image ou une vidéo.
- Lecture automatique de documents (OCR), extraction de champs sur des factures et formulaires.
- Analyse d’autres signaux : séries temporelles de capteurs, logs, transactions pour détection d’anomalies et maintenance prédictive.
Comprendre et générer du langage
- Résumer automatiquement des textes longs, notes de réunion ou articles.
- Traduire et adapter le ton selon la cible.
- Extraire des informations : entités, relations, intentions, sentiments.
- Recherche sémantique et question-réponse sur des bases documentaires.
- Générer du texte avec des LLM : assistants, chatbots, rédaction assistée, aide à la programmation.
Exemple pratique : un LLM peut résumer un compte rendu, en extraire les décisions et générer un courriel de suivi clair et structuré prêt à l’envoi.
Reconnaître et synthétiser la parole
- ASR (reconnaissance vocale) : transcription de réunions, sous-titrage de vidéos.
- TTS (synthèse vocale) : voix naturelles et multilingues pour lecteurs audio, GPS, services clients.
- Diarisation et identification du locuteur pour séparer les voix et attribuer les tours de parole.
- Assistants vocaux : compréhension d’intentions et exécution de commandes en langage naturel.
- Traduction speech-to-text ou speech-to-speech pour rendre des contenus accessibles.
Recommander et personnaliser
Objectif : proposer la bonne expérience à la bonne personne, au bon moment. Les modèles apprennent des préférences et des contextes pour classer les options les plus pertinentes et adapter l’interface en continu.
- Recommandations de produits, contenus ou offres, avec ranking personnalisé.
- Recherche personnalisée et complétion intelligente dans les catalogues et bases de connaissances.
- Next-best-action : messages, promotions et parcours adaptés en temps réel.
- Segmentation et scores prédictifs d’engagement, de churn ou de valeur à vie client.
Au fil des années, ces capacités ont rendu possibles des applications très visibles : reconnaissance d’images médicales, conduite assistée et autonome, assistants conversationnels, recherche d’informations à grande échelle.
L’IA dans le monde professionnel
Presque toutes les industries sont affectées par l’IA, le Machine Learning et le Deep Learning y jouent un grand rôle. Pour passer de la curiosité aux résultats, adoptez une approche par métiers avec des cas d’usage ciblés, des jeux de données bien gouvernés et des indicateurs clairs de performance.
Synthèse actionnable : identifiez un processus coûteux ou risqué, vérifiez la disponibilité des données, démarrez un pilote sur un périmètre réduit, puis industrialisez avec des contrôles qualité et un suivi de dérive des modèles.
Santé (imagerie, aide au diagnostic)
Cas concret : dans les métiers de la santé, il existe déjà des applications pour automatiquement diagnostiquer un patient. En imagerie, des réseaux de neurones détectent des fractures ou des nodules pulmonaires à partir de radiographies et scanners, priorisent les examens et proposent une aide à la décision. Détection automatique d’une fracture à l’aide du Deep Learning, puis validation par le radiologue pour le compte rendu.
Conséquences et enjeux qualité : amélioration de la sensibilité et réduction du temps de lecture, mais aussi nécessité de protocoles de validation clinique, traçabilité des versions de modèles, seuils d’alerte et double lecture humaine sur les cas limites. Par où commencer : cadrer une pathologie, constituer un jeu de données annotées avec consentement, définir des métriques (sensibilité, spécificité, temps moyen par examen) et intégrer l’outil dans le PACS/flux existant.
Industrie (maintenance prédictive, contrôle qualité)
Cas concret : en maintenance prédictive, des modèles apprennent les signatures de vibration, température et intensité moteur pour anticiper une panne et planifier l’intervention. Sur ligne, la vision par ordinateur effectue un contrôle qualité 100 %, repère rayures, défauts d’assemblage ou non-conformités dimensionnelles en temps réel.
Données et preuves attendues : baisse mesurable des arrêts non planifiés, amélioration du TRS, diminution des rebuts et retouches. Bonnes pratiques : démarrer sur un équipement critique, instrumenter les capteurs, créer un historique étiqueté pannes/états, comparer avant/après sur des KPI comme le temps moyen entre pannes, le coût de maintenance par unité et le taux de faux rejets en contrôle visuel.
Finance & assurance (fraude, scoring, risque)
Cas concret : en détection de fraude, des réseaux profonds combinent signaux transactionnels et comportements pour bloquer en quasi temps réel les opérations suspectes. En assurance, des modèles évaluent le risque et priorisent les sinistres à examiner, tout en accélérant l’onboarding avec un scoring plus fin.
Données, preuves et cadre : ces cas d’usage sont mûrs et fortement régulés. On vise une hausse du taux de détection au même niveau ou avec moins de faux positifs, une AUC en progression et des délais de traitement réduits. Exigences clés : explicabilité adaptée au métier, documentation des jeux de données, contrôles de biais, suivi de dérive et gouvernance des modèles pour l’audit.
Mobilité et véhicules autonomes
Explicatif : la conduite assistée et autonome s’appuie sur la fusion de capteurs (caméras, lidar, radar, GPS/IMU). Les réseaux de neurones détectent piétons et voies, estiment la profondeur, suivent les objets et alimentent la planification de trajectoire. La redondance capteur-modèle renforce la sécurité dans des conditions variées.
Cas concret : systèmes d’aide au maintien dans la voie et freinage d’urgence automatisé, entraînés sur des millions d’images et séquences, testés en simulation et sur pistes. Pour déployer, constituer un data lake de scénarios, outiller l’annotation, définir des tests de régression sécurité, puis embarquer les modèles optimisés sur calculateur bord avec télémétrie pour le monitoring.
Le Deep Learning comme solution dans le e-commerce
Le secteur du commerce électronique génère d’immenses volumes de données. Bien utilisées, ces données deviennent un véritable levier de valeur. Le Deep Learning facilite la gestion et l’analyse à grande échelle, automatise l’analyse prédictive et rapproche les expériences d’achat des attentes de chaque client. Concrètement, une boutique en ligne peut proposer des produits plus pertinents, mettre en évidence des préférences et offrir une attention personnalisée tout au long du parcours.
Objectif de cette section : conserver un focus e-commerce très opérationnel, et relier chaque cas d’usage à des KPI métier mesurables.
| Cas d’usage DL | Objectif métier | KPI e-commerce |
|---|---|---|
| Recommandations personnalisées | Augmenter la valeur par commande et accélérer la découverte catalogue | AOV, taux de conversion, CTR recommandation, rétention, revenu par visite |
| Recherche visuelle et enrichissement produit | Réduire la friction de recherche et améliorer la qualité des fiches | Taux de clic en recherche, taux de zéro‑résultat, temps jusqu’à l’ajout panier, complétude attributs |
| Prévision de la demande et pricing dynamique | Mieux piloter les stocks et optimiser la marge | Précision de prévision, taux de rupture, rotation stock, marge, élasticité prix |
| Détection de fraude et lutte contre les bots | Sécuriser paiements et trafic | Taux de fraude, chargeback, faux positifs, qualité du trafic, disponibilité site |
Personnalisation et moteurs de recommandation
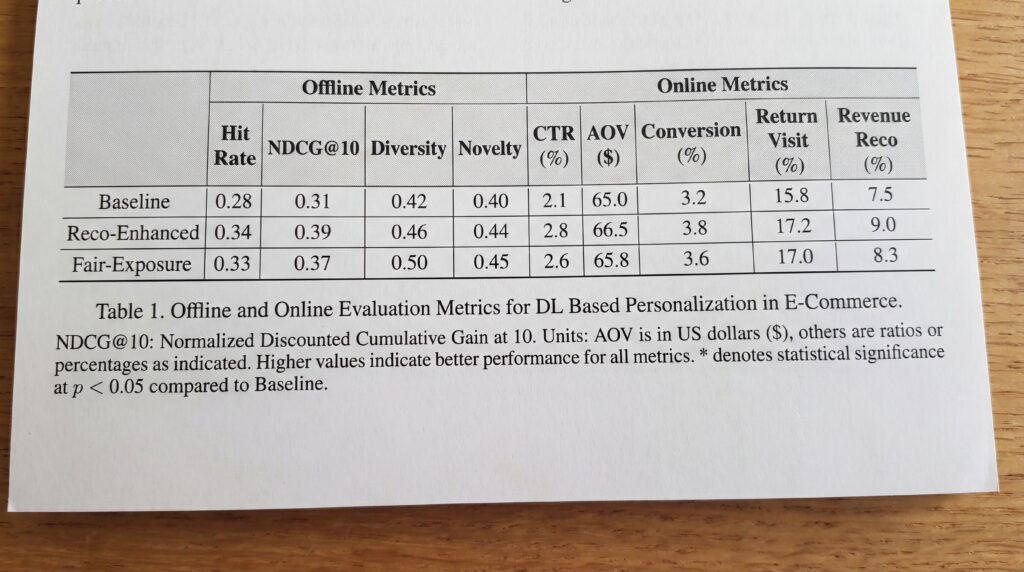
Pratique : les réseaux de neurones apprennent les affinités entre utilisateurs, produits et contextes (saison, device, source d’acquisition). On combine historique de navigation, séquences d’événements et signaux temps réel pour générer des blocs du type : « Parce que vous avez vu », « Complète parfaitement », « Tendance près de chez vous ». Les architectures séquentielles (par exemple modèles à attention) excellent pour capter l’ordre des vues et des ajouts panier en session.
Données et preuves : mesurer l’impact via tests A/B et cohortes. Suivre : CTR des carrousels, AOV, taux de conversion, taux de retour visite, part du revenu assisté par reco, diversité et couverture du catalogue. En amont, contrôler précision hors ligne (hit rate, NDCG), diversité, nouveauté, et vérifier l’équité d’exposition produits.
Recherche visuelle et enrichissement produit
Explicatif : la vision par ordinateur extrait des représentations d’images pour mesurer la similarité visuelle, suggérer des alternatives proches et compléter automatiquement des attributs (couleur, motif, matière). Les mêmes modèles servent à la modération des contenus générés par les utilisateurs et à la détection d’images trompeuses.
Cas concret : un visiteur charge la photo d’un jean. Le moteur renvoie des coupes et teintes similaires, propose la ceinture assortie et corrige la fiche produit si l’attribut « délavage » manque. Résultats attendus : baisse des recherches sans résultat, plus d’ajouts panier issus de la recherche, meilleure complétude d’attributs pour le SEO et les filtres.
Prévision de la demande et pricing dynamique
Explicatif : on combine séries temporelles et apprentissage séquentiel pour prévoir la demande par référence et canal, en intégrant promotions, saisonnalité, calendrier marketing et signaux externes. Les mêmes signaux alimentent un moteur de tarification dynamique qui évalue l’élasticité et propose des prix compatibles avec vos contraintes métier.
- Pipeline type : agrégation journalière hebdomadaire, détection d’anomalies, modèles séquentiels, hiérarchisation par familles produits et magasins, recalage de cohérence.
- Pricing : estimation élasticité, scénarios marge vs volume, garde‑fous réglementaires et seuils de marque, mise à jour cadencée par canal.
- KPI à suivre : MAPE ou WAPE, taux de rupture, surstock, marge brute, délai de rotation, revenu incrémental par expérimentation tarifaire.
Détection de fraude et lutte contre les bots
Problème : la fraude paiement et le trafic automatisé nuisent à la marge, à la qualité des données et à la disponibilité du site. Les réseaux de neurones apprennent des schémas subtils dans les transactions et les parcours pour bloquer en temps réel sans dégrader l’expérience des clients légitimes.
- Scores temps réel sur transactions : encodage séquentiel du panier et des tentatives, empreinte appareil, géolocalisation cohérente, historique client.
- Détection d’anomalies : autoencodeurs pour comportements rares, alertes sur dérives de signaux clés.
- Graphes de relations : liens entre cartes, adresses, emails et appareils pour repérer des réseaux frauduleux.
- Protection trafic : classification de sessions bot vs humain, limites de rythme et défis adaptatifs seulement pour risques élevés.
- KPI : taux de fraude, chargebacks, faux positifs, temps moyen de décision, santé du taux d’autorisation.
Données et préparation : pourquoi sont‑elles cruciales ?

Les modèles de Deep Learning excellent quand la donnée est bien préparée. La qualité des jeux d’entraînement et de validation reste le premier facteur de performance, souvent sous‑traité face au choix d’architecture. Une bonne préparation réduit l’erreur, améliore la robustesse et limite les biais qui peuvent se traduire par des décisions inéquitables.
- Qualité intrinsèque : exactitude, complétude, cohérence, fraîcheur, absence de doublons.
- Représentativité : couverture des cas fréquents et des cas rares, équilibre des classes.
- Préparation rigoureuse : nettoyage, normalisation, gestion des valeurs manquantes, protection contre les fuites de données entre entraînement et test.
- Gouvernance : versionning des jeux, traçabilité des sources, métadonnées claires, licences et droits d’usage documentés.
- Découpage fiable : séparation entraînement, validation et test, idéalement stratifiée quand les classes sont déséquilibrées.
Qualité, biais et étiquetage
En apprentissage supervisé, l’algorithme est guidé par des exemples étiquetés. Si les étiquettes sont bruitées, ambiguës ou incomplètes, le modèle apprend des règles erronées qui se traduisent par une baisse de précision et des biais. La définition d’une taxonomie claire, des consignes d’annotation partagées et un contrôle qualité systématique sont essentiels : double annotation puis arbitrage, mesure de l’accord inter‑annotateurs (par exemple kappa), échantillonnage équilibré, vérification ciblée des cas limites.
Conséquences d’une donnée de faible qualité : surapprentissage sur des corrélations fortuites, dégradation hors distribution, erreurs récurrentes sur des sous‑populations, risques de non‑conformité si des attributs protégés sont inférés par procuration. À l’inverse, un jeu propre et bien étiqueté améliore à la fois performance et équité, tout en réduisant les coûts d’itération modèle.
Augmentation de données et jeux publics
- Augmentation classique : pour l’image (rotations, recadrages, variations de couleur), pour l’audio (time‑stretch, pitch‑shift), pour le texte (paraphrases, back‑translation, masquage de tokens).
- Déséquilibre des classes : ré‑échantillonnage, pondération des pertes, techniques tabulaires comme SMOTE.
- Apprentissage avec peu d’exemples : transfer learning, réglage fin de modèles pré‑entraînés, pseudo‑étiquetage, weak supervision.
- Données synthétiques encadrées : génération contrôlée pour couvrir des cas rares, avec vérification de non‑réidentification et de dérive de distribution.
- Jeux publics de référence : utiles pour démarrer, évaluer des approches et comparer des modèles, sous réserve d’analyser licences, biais connus et adéquation au cas d’usage.
En pratique, commencez par un modèle pré‑entraîné et un petit protocole d’augmentation, puis élargissez la couverture via l’annotation active : le modèle propose des exemples incertains que l’on fait annoter en priorité. Documentez chaque jeu avec une fiche de données (sources, objectifs, limites) et alignez le schéma d’étiquetage entre données publiques et internes.
Confidentialité et RGPD : que faut‑il prévoir ?
Les jeux d’entraînement peuvent contenir des données personnelles. Le RGPD s’applique dès qu’une personne est identifiable, directement ou indirectement. Il faut définir une base légale appropriée (intérêt légitime, contrat, consentement selon les cas), respecter la finalité déclarée, minimiser les données collectées, limiter la durée de conservation, sécuriser l’accès et informer les personnes concernées. Pour des traitements susceptibles d’engendrer des risques élevés, une analyse d’impact (DPIA) et l’implication du DPO sont requises. Les recommandations de la CNIL insistent sur la transparence, la gestion des biais, la documentation des jeux et la traçabilité des versions.
En pratique : privilégiez l’anonymisation robuste ou, à défaut, la pseudonymisation, isolez les attributs sensibles, contractualisez avec vos sous‑traitants, évitez l’export de données hors UE sans garanties adéquates, mettez en place des procédures d’exercice des droits (accès, rectification, effacement), journalisez les flux de données et les accès. N’entraînez pas sur des données dont la licence ou l’origine est incertaine, et relisez systématiquement les licences des jeux publics avant usage.
Évaluer un modèle de deep learning
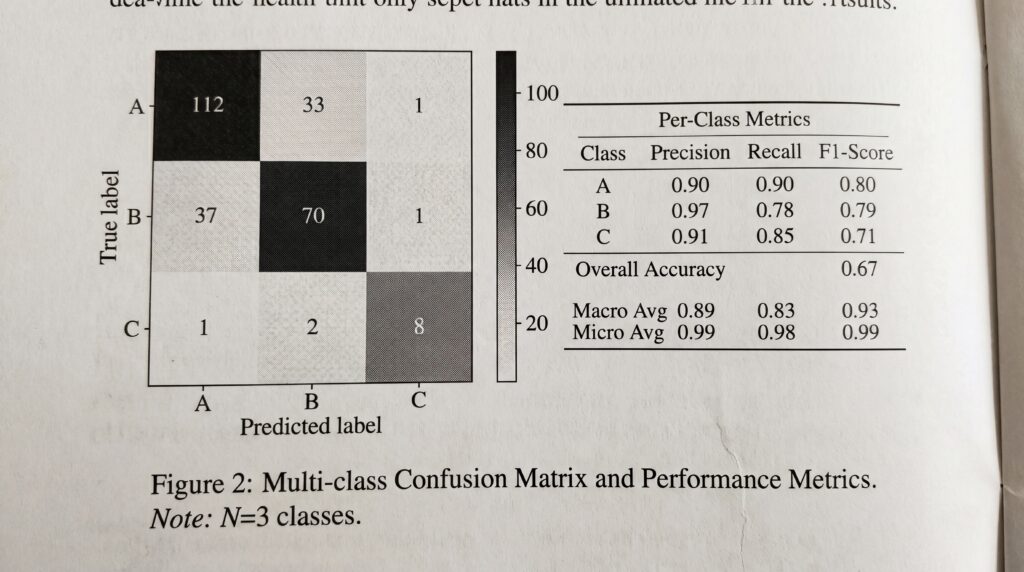
Évaluer un modèle, ce n’est pas seulement regarder un score unique. Il s’agit de juger sa capacité à généraliser sur des données nouvelles, en fonction des coûts d’erreur du métier, tout en évitant les pièges méthodologiques. Dans un problème de classification, par exemple, la dernière couche softmax retourne des probabilités par classe : on choisit alors un seuil et une métrique cohérente avec l’usage, plutôt que l’accuracy par défaut.
En synthèse : définissez le but métier et les erreurs les plus coûteuses, choisissez la ou les métriques adaptées, séparez rigoureusement les jeux de données, validez par cross‑validation quand les données sont limitées, et contrôlez les biais classiques (données fuyantes, classes déséquilibrées, sur‑ajustement aux benchmarks).
Métriques clés (accuracy, précision, rappel, F1, AUC)
| Métrique | Ce que cela mesure | Quand la privilégier | Limites et pièges |
|---|---|---|---|
| Accuracy (exactitude) | Part des prédictions correctes sur l’ensemble | Classes équilibrées et coûts d’erreur similaires | Peut être trompeuse si la classe positive est rare |
| Précision | TP / (TP + FP) : fiabilité des positifs prédits | Faux positifs coûteux (fraude, modération) | Peut masquer un rappel trop faible |
| Rappel | TP / (TP + FN) : capacité à retrouver les positifs | Faux négatifs coûteux (dépistage médical, sécurité) | Peut augmenter au détriment de la précision |
| F1-score | Moyenne harmonique précision‑rappel | Arbitrage global quand les classes sont déséquilibrées | Cache l’asymétrie P/R ; préciser macro/micro selon le cas |
| AUC‑ROC | Qualité de classement TPR vs FPR sur tous les seuils | Comparer des modèles quand les coûts sont inconnus | Moins informative avec forte rareté ; préférer parfois AUC‑PR |
| AUC‑PR | Zone précision‑rappel sur tous les seuils | Classes positives rares, recherche de vrais positifs | Sensible à la prévalence ; baseline = taux de positifs |
Astuce : en classification multi‑classe, reportez aussi la matrice de confusion et les métriques par classe. Pour des sorties probabilistes, suivez la calibration (ex. courbes fiabilité) et une perte comme la log‑loss.
Validation, cross‑validation et jeux de test
Une bonne évaluation repose sur une séparation claire des données et sur des protocoles qui évitent toute contamination entre entraînement et évaluation. Le jeu de test doit rester hors de portée pendant le développement et ne servir qu’à l’estimation finale.
- Découpage conseillé : entraînement, validation (choix d’architecture, seuils, arrêt anticipé), test final unique.
- Cross‑validation k‑fold (souvent stratifiée) si peu de données : moyennez les scores et la variance. Pour le réglage d’hyperparamètres, utilisez une nested CV.
- Données temporelles : utilisez des découpages chronologiques progressifs (pas de mélange passé/avenir).
- Groupes apparentés (utilisateurs, produits, patients, images quasi‑dupliquées) : appliquez un GroupKFold ou un split par groupe pour éviter les fuites.
- Pipelines : tout prétraitement apprenant (normalisation, PCA, sélection de variables, encodage cible) doit être ajusté uniquement sur l’entraînement de chaque fold, puis appliqué au reste.
- Stabilité : fixez les graines aléatoires, répétez les runs, reportez des intervalles de confiance quand c’est possible.
Quelles erreurs d’évaluation reviennent souvent ?
- Se fier à l’accuracy avec des classes déséquilibrées, au lieu d’analyser précision, rappel, F1 et AUC‑PR.
- Fuite de données (data leakage) via des prétraitements ajustés sur tout le dataset, des fuites temporelles ou des doublons entre jeux.
- Sur‑mesure aux benchmarks/leaderboards : itérations répétées sur le jeu de validation ou, pire, sur le test.
- Mauvais découpage pour séries temporelles ou groupes liés.
- Seuils optimisés sur le test au lieu du jeu de validation.
- Rapporter un score ponctuel sans variance, sans analyse par sous‑populations ni vérification de la calibration.
- Ignorer les coûts d’erreur et les contraintes réelles : latence, mémoire, énergie, robustesse hors distribution.
Avec quels outils et matériels démarrer ?
Pour passer de la théorie à la pratique, visez un kit simple, robuste et économique. Les modèles de Deep Learning fonctionnent d’autant mieux qu’ils disposent de beaucoup de données et de puissance de calcul, il est donc utile d’anticiper vos besoins dès le départ.
- Environnement Python prêt à l’emploi : Python 3.x, conda ou
venvpour isoler vos dépendances, gestion des GPU via les pilotes et bibliothèques CUDA/cuDNN quand c’est nécessaire. - Outils de développement : VS Code ou PyCharm, JupyterLab pour l’exploration, Git et un hébergeur de dépôt pour versionner code et données.
- Données et annotation : jeux publics pour démarrer, feuilles de route d’annotation claires, formats standardisés, échantillons équilibrés.
- Accès au calcul : un portable ou une station avec GPU pour les prototypes, puis du cloud quand l’entraînement s’intensifie. Pour débuter gratuitement, des notebooks hébergés conviennent pour des essais courts.
Frameworks : PyTorch, TensorFlow, Keras
Les trois écosystèmes couvrent la majorité des besoins. Choisissez selon le cas d’usage, la maturité de votre équipe, et vos contraintes de déploiement.
- PyTorch : très apprécié en R&D et en prototypage grâce à son style Pythonique et son exécution dynamique. Large écosystème de modèles et de tutoriels, intégrations avec les bibliothèques de suivi d’expériences et de déploiement serveur.
- TensorFlow : orienté production, avec TensorFlow Extended pour les pipelines et TensorFlow Lite pour le mobile et l’embarqué. Bon choix quand vous ciblez plusieurs plateformes de déploiement.
- Keras : API haut niveau claire pour construire des réseaux rapidement, idéale pour l’apprentissage et les POC. Fréquemment utilisée avec TensorFlow, elle permet de démarrer vite et de structurer proprement vos modèles.
- Compléments utiles : bibliothèques de modèles préentraînés, tableaux de bord de suivi d’expériences, convertisseurs ONNX pour porter un même modèle sur plusieurs moteurs d’inférence.
GPU, TPU et coût énergétique
Les GPU accélèrent les calculs matriciels qui dominent l’entraînement des réseaux de neurones. Les TPU, proposés par certains fournisseurs cloud, sont optimisés pour les charges massives et s’emploient surtout avec TensorFlow. En pratique : pour de la vision ou des petits modèles, un GPU 8 à 12 Go de mémoire vidéo peut suffire, tandis que la génération de texte ou les modèles de grande taille bénéficient de 24 Go et plus, ou d’un entraînement distribué.
Surveillez l’empreinte carbone et le coût : mesure de la puissance consommée, mixed precision (FP16/BF16), early stopping, taille de lot adaptée, échantillonnage et Transfer Learning réduisent temps d’entraînement et énergie. Planifiez vos expériences, regroupez les essais pour limiter les allers-retours, privilégiez si possible des régions d’hébergement à électricité bas carbone.
Entraînement vs inférence, MLOps et déploiement
L’entraînement optimise les paramètres du modèle, l’inférence sert les prédictions. Le premier est intensif en calcul et en I/O, le second est contraint par la latence et le coût par requête. Pensez quantification, distillation et pruning pour réduire taille et latence, et choisissez un moteur d’inférence adapté à votre cible : serveur, edge, mobile.
- Pipeline de prod : ingestion et validation des données, entraînement reproductible, suivi d’expériences et des artefacts, évaluation hors et en ligne, validation éthique et sécurité.
- Packaging et déploiement : export du modèle (SavedModel, TorchScript, ONNX), conteneurisation, service d’inférence avec gestion de versions, canary ou A/B.
- Monitoring : latence p95, taux d’erreur, dérive des données et du modèle, coût par mille requêtes. Définissez des déclencheurs de réentraînement et un plan de retour arrière.
- Cibles : serveur temps réel avec micro-batching, lots asynchrones pour l’analytique, TensorFlow Lite ou Core ML sur mobile, moteurs ONNX pour la portabilité multi-plateformes.
Techniques modernes pour aller plus vite
Pour réduire le temps entre l’idée et la mise en production, les équipes combinent aujourd’hui des approches qui capitalisent sur des modèles existants, limitent la quantité de données à annoter et optimisent l’exécution des modèles en production.
- Réutiliser des modèles déjà entraînés plutôt que de repartir de zéro.
- Adapter finement un modèle à un domaine ciblé avec peu de données.
- Optimiser l’inférence pour baisser les coûts et la latence sans sacrifier la qualité.
- Expérimenter vite, mesurer systématiquement, puis industrialiser ce qui fonctionne.
Transfer learning et fine-tuning
Le transfer learning consiste à partir d’un réseau déjà entraîné sur une tâche générale (images, texte, audio) puis à le spécialiser sur votre cas d’usage. Le fine-tuning ajuste une partie des paramètres du modèle pour apprendre les spécificités de votre domaine. Résultat : beaucoup moins de données annotées à préparer, des coûts d’entraînement réduits, et un time-to-value plus court qu’un entraînement complet.
Cas concret : au lieu d’entraîner un classifieur d’images médicales depuis zéro, on démarre d’un modèle visuel entraîné sur des millions d’images génériques, on remplace la dernière couche et on l’ajuste avec quelques milliers d’exemples étiquetés. En NLP, on peut partir d’un grand modèle de langage et le régler sur des paires question‑réponse propres à l’entreprise. Pour aller plus loin, consultez notre article dédié Transfer Learning.
Modèles pré‑entraînés et foundation models (LLM)
Les foundation models, comme les grands modèles de langage, sont pré‑entraînés sur des corpus massifs pour apprendre des représentations générales. On les réutilise ensuite pour des tâches spécifiques : génération de texte, extraction d’informations, résumé, analyse d’images, etc. Selon les besoins, on peut les exploiter en zéro‑shot ou few‑shot (simple ingénierie de prompts), ou bien via un réglage fin léger pour des performances plus stables.
En pratique : choisir un modèle adapté à la contrainte métier (taille, latence, confidentialité), valider sur un jeu d’évaluation proche du réel, puis décider entre simple “prompting”, ajout de contexte (RAG) ou fine‑tuning. Cette approche évite un entraînement coûteux et accélère fortement l’expérimentation comme le déploiement.
Comment réduire les coûts d’inférence ?
- Quantization : convertir les poids et activations en 8 bits (voire 4 bits) pour diminuer mémoire et temps de calcul. À appliquer après l’entraînement (post‑training) ou à intégrer pendant l’entraînement (quantization‑aware). Attention à contrôler l’impact sur la précision.
- Distillation : entraîner un student plus petit à imiter un modèle teacher plus grand. On conserve une grande partie des performances avec un modèle bien plus rapide, idéal pour l’edge ou les API à fort trafic.
- LoRA / adapters (PEFT) : n’ajuster qu’un petit nombre de paramètres via des modules additionnels. On évite de réentraîner ou stocker l’intégralité du modèle, on charge/décharge les adapters selon la tâche et on maintient des coûts d’inférence maîtrisés.
En comparaison : la quantization cible surtout l’efficacité matérielle, la distillation remplace le modèle par une version compacte, et les adapters privilégient la spécialisation multi‑tâches sans gonfler la taille du cœur du modèle. Ces techniques sont complémentaires et se combinent souvent pour trouver le meilleur compromis qualité, latence et coût.
Quelles sont les limites et défis du deep learning ?

Malgré des progrès spectaculaires, un regard équilibré s’impose. Les réseaux de neurones profonds excellent avec beaucoup de données et de calcul, mais se heurtent à des obstacles récurrents qui impactent les coûts, la fiabilité et la conformité des projets.
- Besoins massifs en données et coût de calcul
- Biais, explicabilité et robustesse des modèles
- Durabilité et empreinte carbone
- Gouvernance, traçabilité et conformité réglementaire
Données massives et coût de calcul
Le problème : le deep learning est gourmand en puissance et en données. Les modèles modernes exigent d’énormes volumes de données, souvent étiquetées, et des ressources matérielles spécialisées pour l’entraînement et l’inférence. Les composants informatiques de plus en plus puissants ont rendu ces modèles possibles, mais leur budget matériel et cloud, leur mise à l’échelle sur plusieurs GPU ainsi que la gestion des files et de la latence deviennent des contraintes majeures, surtout pour les cas d’usage temps réel et les déploiements à grande échelle.
Conséquences : hausse des coûts d’entraînement et d’inférence, délais de mise sur le marché plus longs, complexité d’orchestration distribuée, dépendance à des fournisseurs d’infrastructure, arbitrages entre précision et latence (edge vs cloud), ainsi que dettes techniques liées au stockage, à la qualité et à la gouvernance des données.
Biais, explicabilité et robustesse (attaques adversariales)
Pourquoi c’est critique : les réseaux profonds apprennent des corrélations complexes dans des jeux de données qui peuvent refléter des déséquilibres ou préjugés. Leur fonctionnement reste souvent difficile à interpréter, ce qui complique la confiance, l’audit et la prise de décision en environnements sensibles. Par ailleurs, de petites perturbations d’entrée peuvent provoquer des erreurs, et l’exposition à des données hors distribution ou malicieuses les rend vulnérables.
- Biais : données non représentatives, annotations inégales, dérive dans le temps. Mesures utiles : audit de jeux de données, métriques d’équité, équilibrage et augmentation ciblée.
- Explicabilité : difficulté à justifier une prédiction. Mesures utiles : techniques d’explicabilité adaptées au type de modèle, fiches de modèles et de jeux de données, revue humaine.
- Robustesse et sécurité : attaques adversariales, empoisonnement de données, dérive de distribution. Mesures utiles : tests de robustesse, entraînement adversarial, détection d’anomalies, contrôle d’accès et surveillance continue.
Durabilité et empreinte carbone
Données et constats : l’entraînement et l’inférence à grande échelle consomment beaucoup d’énergie, en particulier sur GPU et accélérateurs. Le volume de calcul, la durée d’entraînement, la région d’hébergement et le refroidissement des centres de données influencent directement l’empreinte carbone globale d’un projet.
Bonnes pratiques : privilégier le transfert d’apprentissage et le réglage fin plutôt que l’entraînement complet, dimensionner finement les modèles, appliquer la distillation et la quantification, utiliser des lots et du caching pour l’inférence, choisir des régions et fournisseurs à faible intensité carbone lorsque c’est possible, suivre des indicateurs d’énergie et d’émissions dans le pipeline MLOps, et arrêter tôt les expériences non prometteuses.
Gouvernance et conformité
Enjeu : la conformité impose de prouver la traçabilité des données et des versions de modèles, de documenter les limites, d’évaluer les risques et de respecter les cadres applicables aux données personnelles et aux usages sensibles. Sans cette gouvernance, les risques juridiques, réputationnels et opérationnels augmentent fortement.
- Traçabilité : lignage des données et des features, versions d’entraînement, jeux de tests, dépendances logicielles, paramètres et jeux de poids.
- Documentation : fiches de modèles et de jeux de données, description des cas d’usage autorisés, limites connues, plan de monitoring, gestion des incidents.
- Risques légaux : respect de la vie privée, droits sur les données et sur les contenus générés, obligations sectorielles, gestion des consentements et des demandes des utilisateurs.
- Contrôles internes : validation humaine pour les décisions à impact, procédures d’audit, indicateurs d’équité et de performance en production, désactivation et retrait rapides en cas de dérive.
Sources
Pour aller plus loin, retrouvez des ressources fiables classées par type : articles de référence, tutos, cours ouverts, jeux de données, frameworks.
Articles de référence
- F. Rosenblatt (1958), The perceptron: a probabilistic model for information storage and organization in the brain (PDF)
- G. Cybenko (1989), Approximation by Superpositions of a Sigmoidal Function (PDF)
- CNIL, Apprentissage profond (deep learning)
- IBM Think, Qu’est-ce que le deep learning ?
- Oracle, Deep learning : définition et usages
Tutos
- Vidéo : Introduction au Deep Learning (YouTube)
- Vidéo : Tutoriel Deep Learning (YouTube)
Cours ouverts
- OpenClassrooms : Appréhendez le Deep Learning
Datasets
- MNIST (chiffres manuscrits)
- CIFAR-10/CIFAR-100 (images d’objets)
- ImageNet (large base d’images annotées)
Frameworks
- TensorFlow
- PyTorch
- Keras
- Hugging Face Transformers



